What is "Reference Data" - and why does your AI depend on getting it right?
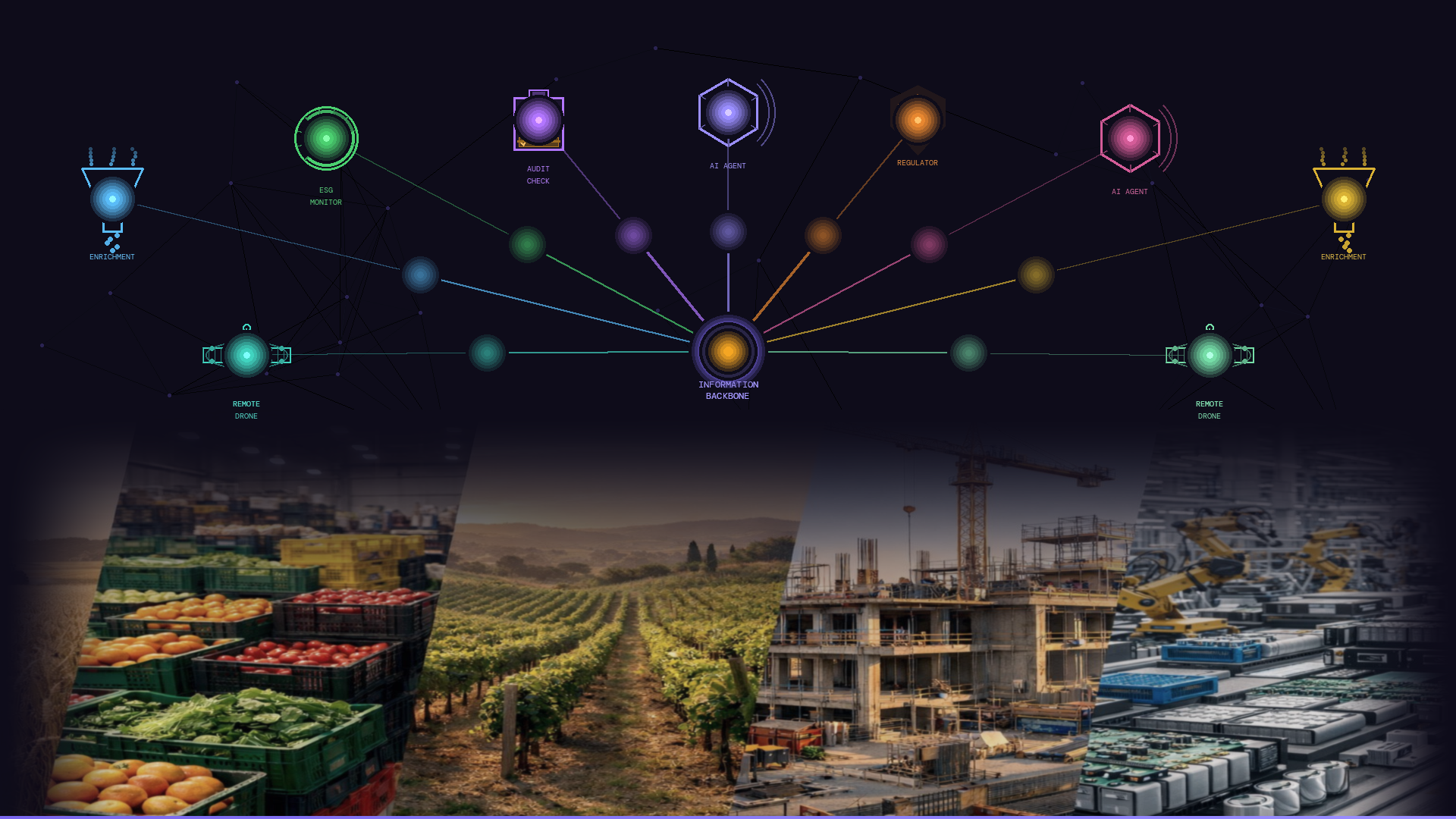
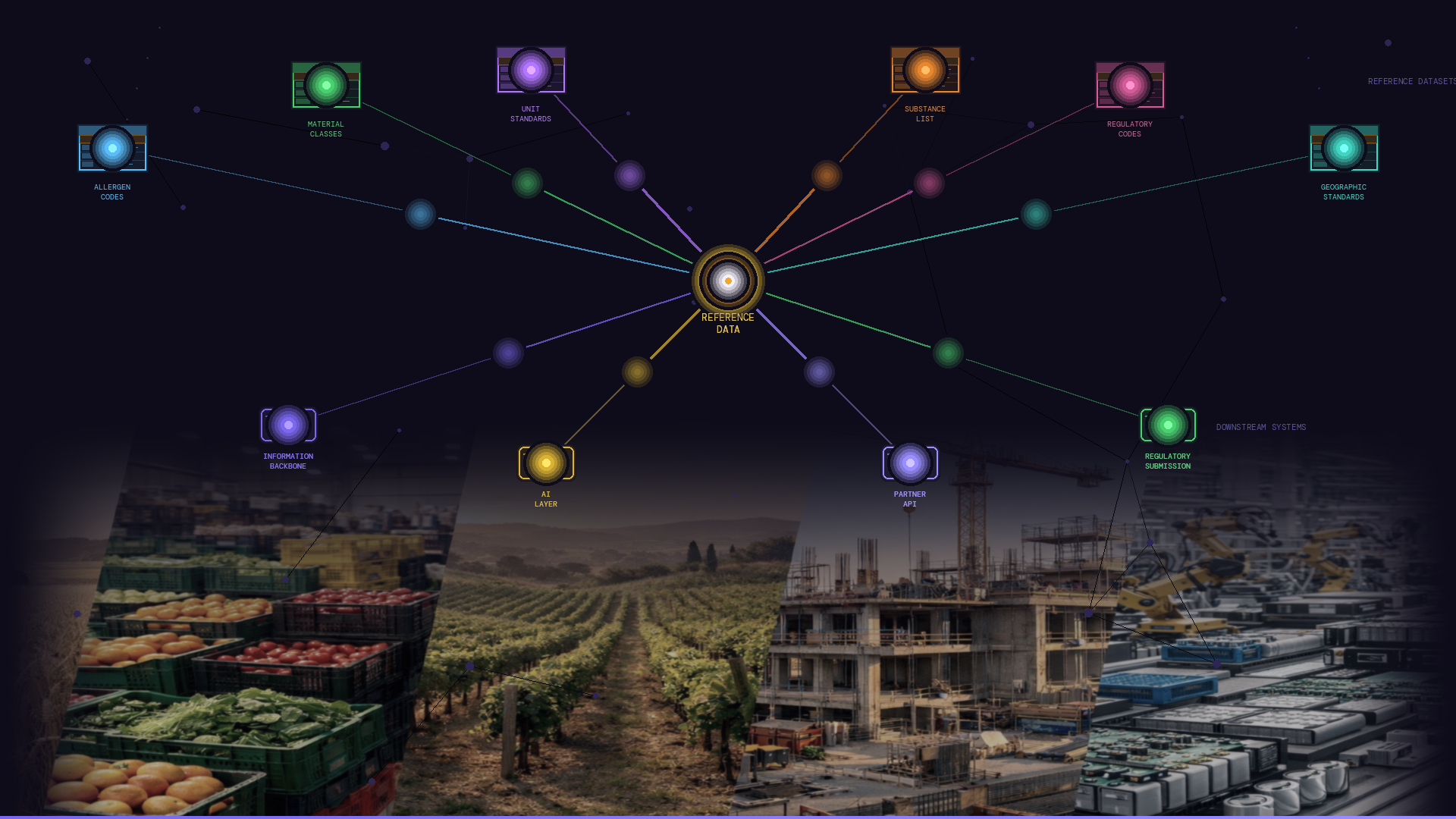
Governed, shared reference data is the stable vocabulary your backbone speaks in. Without it, every system downstream is guessing.
2 articles
Reference data is the controlled set of authorised values - classification schemes, regulatory substance lists, standard unit definitions, recognised allergen codes - that the information backbone draws from when it needs to express something precisely. It is what turns a substance code from a string of characters into a defined entity with known properties and known relationships to everything else in the model. Reference data comes from two sources: external standards (regulatory bodies, industry classification schemes, third-party taxonomies) and organization-specific values (internal product codes, proprietary classifications, domain-specific workflow terms). Both require active governance: knowing who owns each dataset, how updates are managed, and how changes propagate to the systems that depend on them. Without governed reference data, even a well-structured backbone speaks in dialects: one system's 'material' is not the same as another's, and every downstream consumer - human or machine - is left to interpret the difference.
Governed, shared reference data is the stable vocabulary your backbone speaks in. Without it, every system downstream is guessing.
In regulated and high-trust environments, AI reliability isn't a model problem. It's a foundation problem.